Unlocking Techno-Strategic Synergy: Solving Digital Dilemmas for Exponential Success

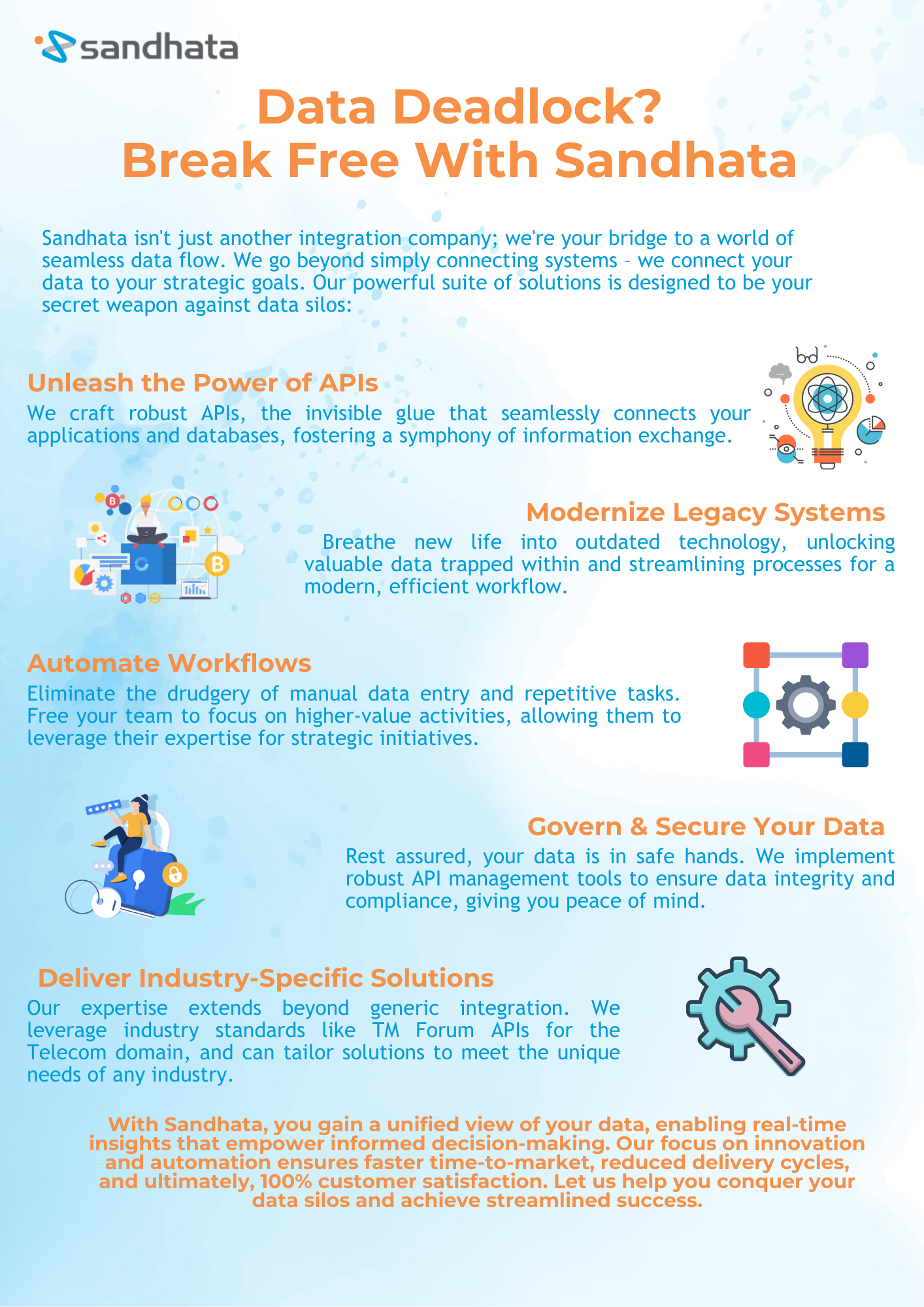



Imagine multiple messages waiting in a message catch event.
When a single throw event is triggered, the data is processed without any issues. However, if multiple message events are thrown simultaneously, only the first one is successfully processed, while the others fail.
This is because the message catch event is busy handling the first message event.
We recently spotted this issue with Camunda 7’s message catch event.
Our team of experts fabricated a groundbreaking “Generic Message Buffering” logic, with which we’ve revolutionised the way messages are processed asynchronously, effectively resolving any scenario you may encounter.
Fig. 1.1 unveils the powerful list of message catch events eagerly awaiting the trigger.
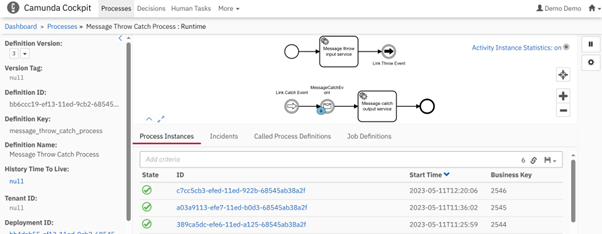
Fig1.1
In Figure 2.1, we present the logic for Generic Message Buffering. By sending a POST request, we can activate the BPM process described below. Additionally, we have the ability to specify the retry count and retry delay as request parameters. Once the request is triggered, we conduct a basic validation to ensure all necessary information, such as message name, payload, process instance id, and business key, is present.
If all the required data is available, we proceed to send the message to its destination within the “Message Send Task” depicted in Figure 2.1.
If the message is successfully picked up and processed by the message catch event, we encounter no issues.
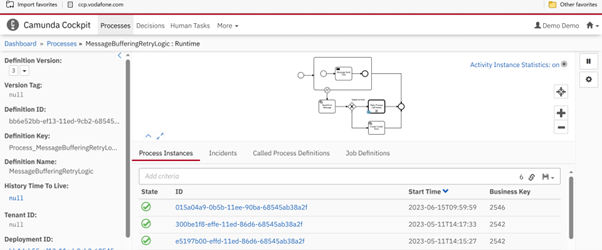
Fig2.1
In a situation where the message catch event is already occupied processing another message, throwing our own message will result in failure. This is a common occurrence in real-time scenarios, and it is up to the developers to determine how the flow should be handled in such cases.
In our specific case, the failed message will be caught by the boundary event. The error message will then be examined in detail within the “Read Error Message” process (Fig 2.1).
In the event of an error, we can:
When encountering a retriable error, we make an attempt to retry the operation. The number of retries and the delay between retries is determined by the input request.
In the context of re-try logic, there are two potential scenarios to consider:
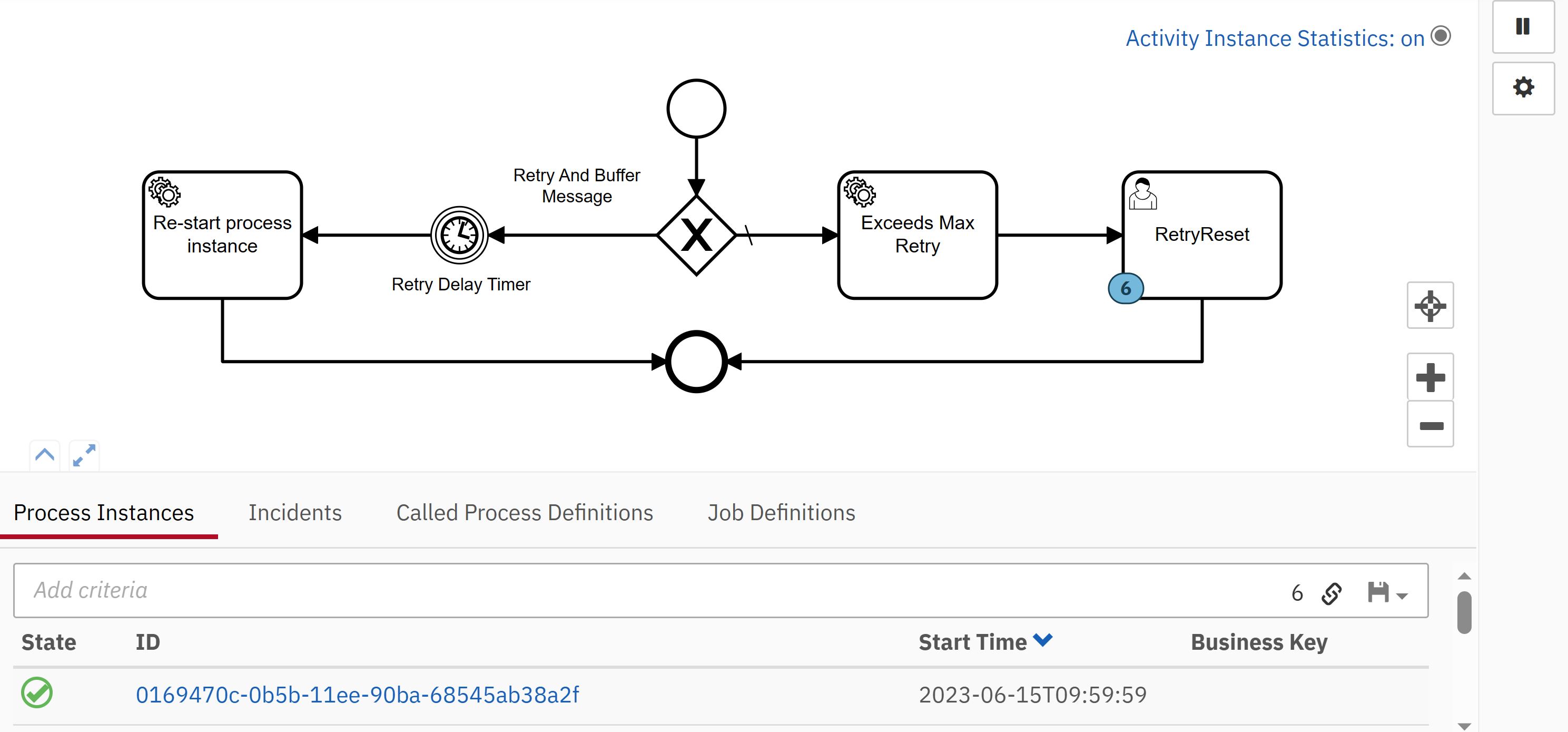
Fig 3.1
If the maximum re-try attempts have been exceeded and the message still hasn’t been delivered successfully, it will require manual re-processing (see Fig 3.2).
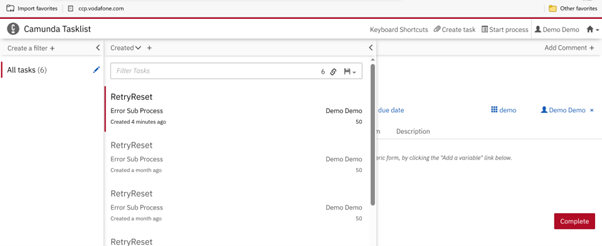
Fig 3.2
In order to optimize efficiency, it is vital that both the target BPM and the message buffering BPM are connected to a centralized database. This will allow for seamless integration and streamlined performance. Maintaining a unified database instance is key to achieving optimal results.